Cuando oímos la palabra Estadística, lo más habitual es que pensemos en encuestas, porcentajes o diagramas de barras. Usamos la Estadística para calcular el salario medio en una ciudad, el riesgo de una cierta operación bancaria o la probabilidad de ganar unas elecciones. Pero… ¿qué pasa cuando, además del cuánto, nos importa el dónde?
La Estadística Espacial es una poderosa rama de la Estadística, que se centra en analizar datos que disponen de una ubicación geográfica. ¿Dónde se concentran los incendios forestales? ¿Cuáles son las regiones con mayor incidencia de ciertas enfermedades? ¿Cómo se distribuyen los accidentes de tráfico en una ciudad? Estas y otras muchas preguntas solo pueden entenderse si incorporamos el espacio y las coordenadas en nuestros análisis. En este artículo te invito a descubrir cómo los mapas pueden contar historias que los números, por sí solos, no alcanzarían a explicar.
Mapeando el cólera: un médico en el origen de la Estadística Espacial
Londres, 1854. La ciudad atravesaba una de las muchas epidemias de cólera que azotaban al mundo en aquella época. En particular, el barrio de Golden Square fue testigo de un brote inusualmente virulento: ¡más de 700 personas murieron en apenas diez días! En aquel tiempo, la teoría microbiana de la enfermedad, esa que sostiene que virus y bacterias microscópicos son los responsables de estas, aún no se conocía. En su lugar, se pensaba que las dolencias eran provocadas por los “malos aires” o “malos olores” que emanaban de terrenos o aguas infestadas.
John Snow, un reputado médico de la época, no comulgaba con esta teoría y decidido a comprender el origen de aquel brote, comenzó a recorrer el barrio mapa en mano, visitando una a una las viviendas y preguntando si alguien había presentado síntomas compatibles con el cólera. Cada vez que obtenía una respuesta afirmativa, marcaba con un pequeño rectángulo negro la ubicación. Lo que consiguió no fue solo un censo detallado del brote, sino algo más revelador: una imagen espacial de la enfermedad, ver Figura 1 (izquierda).
Al observar el mapa resultante, Snow detectó un patrón: la mayoría de los casos estaban agrupados en torno a un punto concreto de la ciudad: la fuente de agua pública ubicada en Broad Street, ver Figura 1 (derecha). Sospechando que el agua estaba contaminada, pidió que se deshabilitara el surtidor. Las autoridades accedieron, aunque no sin escepticismo, y poco después, los contagios disminuyeron drásticamente.
Este episodio marcó un antes y un después. Aunque Snow no hablaba aún de “Estadística Espacial”, su método ya contenía los elementos clave: datos georreferenciados, visualización y análisis de patrones. Su mapa contribuyó a frenar una epidemia a la par que sentaba las bases para una nueva forma de entender los datos.
La tríada de la Estadística Espacial: puntos, mallas y regiones.
No todos los datos espaciales son iguales; el tipo y la forma de la información que manejamos influyen directamente en cómo la analizamos. A grandes rasgos, podemos clasificarla en tres grupos que determinan las tres grandes áreas de esta disciplina: Geoestadística, Procesos Puntuales y Datos de Área.
Geoestadística
Imagina que hay sensores de calidad del aire repartidos por una región. Cada uno registra la concentración de cierto contaminante en un punto concreto. Pero claro, no podemos llenar cada metro cuadrado con un sensor. ¿Cómo saber qué ocurre en los lugares intermedios donde no hay mediciones directas? La geoestadística se encarga de resolver este tipo de problemas.
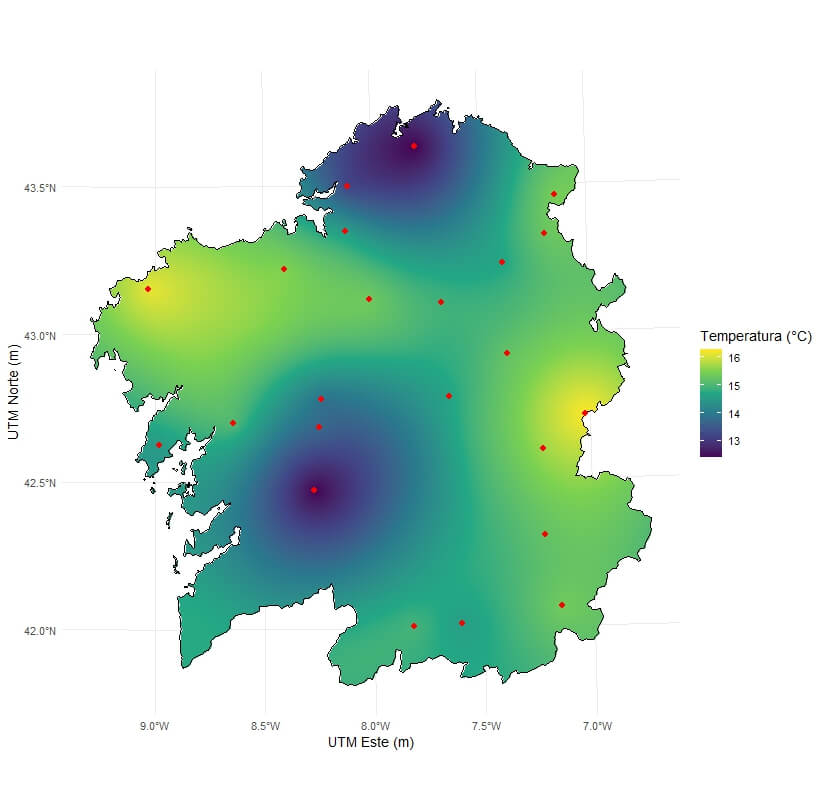
Usando técnicas como la interpolación espacial, podemos predecir valores en zonas sin observaciones, basándonos en cómo se comportan los valores vecinos. Esto permite generar mapas continuos que muestran, con transiciones suaves de color, cómo varía una magnitud en todo el territorio. Es lo que ocurre cuando consultamos un mapa de lluvias, de temperaturas o de contaminación: detrás hay una red de datos dispersos y un modelo que los convierte en una superficie interpretable. Se puede ver un ejemplo simulado del territorio gallego en la Figura 2.
Procesos puntuales
Aquí lo importante no es cuánto vale una variable en un punto, sino las coordenadas donde ocurre el evento (incendio forestal, accidente de tráfico…). Un ejemplo de la representación gráfica de este tipo de datos puede verse en la Figura 3.
Cada observación (evento de interés) se representa como un punto en el mapa con el que buscamos responder a preguntas como: ¿están los sucesos agrupados o dispersos? ¿Existen zonas “calientes” donde ocurren con mayor frecuencia? Herramientas como los mapas de calor permiten visualizar fácilmente zonas donde los eventos tienden a concentrarse. Formalmente, lo que se representa en estos mapas es la intensidad del proceso, una medida que indica cuántos eventos esperamos por unidad de superficie.
Además, no se trata solo de contar puntos. Muchas veces, utilizamos modelos matemáticos que nos permiten incorporar factores que influyen en la aparición de esos eventos: el tipo de vegetación en los incendios o la densidad de tráfico en los accidentes. Estos modelos ayudan no solo a describir lo que ha ocurrido, sino también a predecir y simular lo que podría pasar.
Datos de área
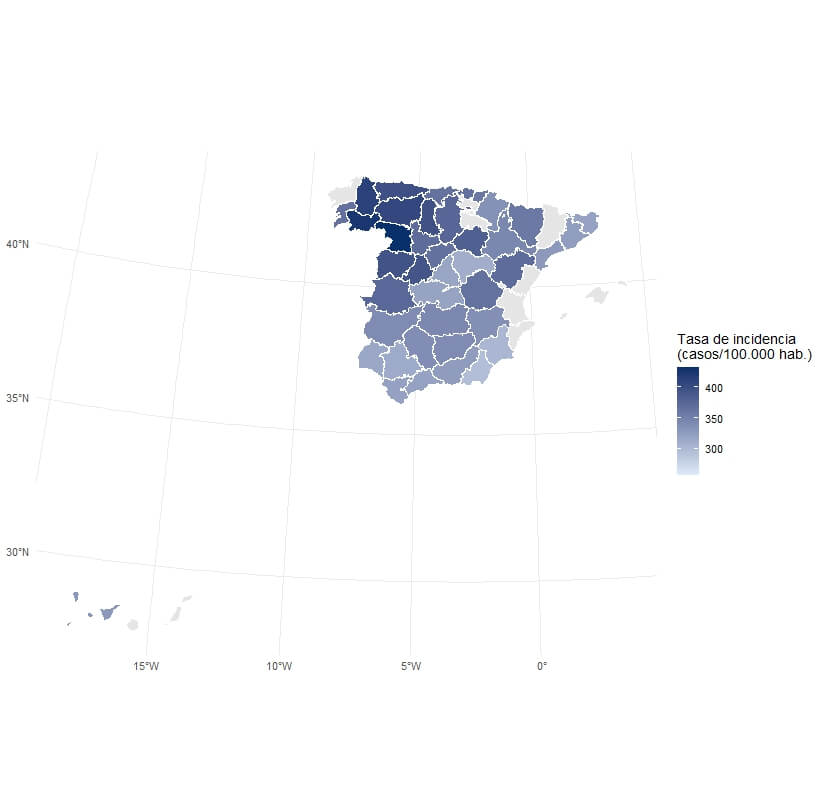
Se caracterizan porque los datos que tenemos no se refieren a puntos concretos, sino a zonas geográficas definidas, como barrios, provincias o áreas sanitarias. Esto ocurre, por ejemplo, con los mapas que muestran la incidencia de una enfermedad, ver Figura 4. En estos casos, cada área tiene asociado un valor, y el análisis se centra en comparar regiones entre sí.
Este enfoque es habitual cuando los datos proceden de registros administrativos o cuando hay que preservar la privacidad. Por ejemplo, en salud pública no se publica la dirección exacta de los pacientes, ofreciendo en su lugar tasas por zonas que impidan la identificación personal.
La Estadística Espacial está presente en tu día a día (aunque no lo sepas)
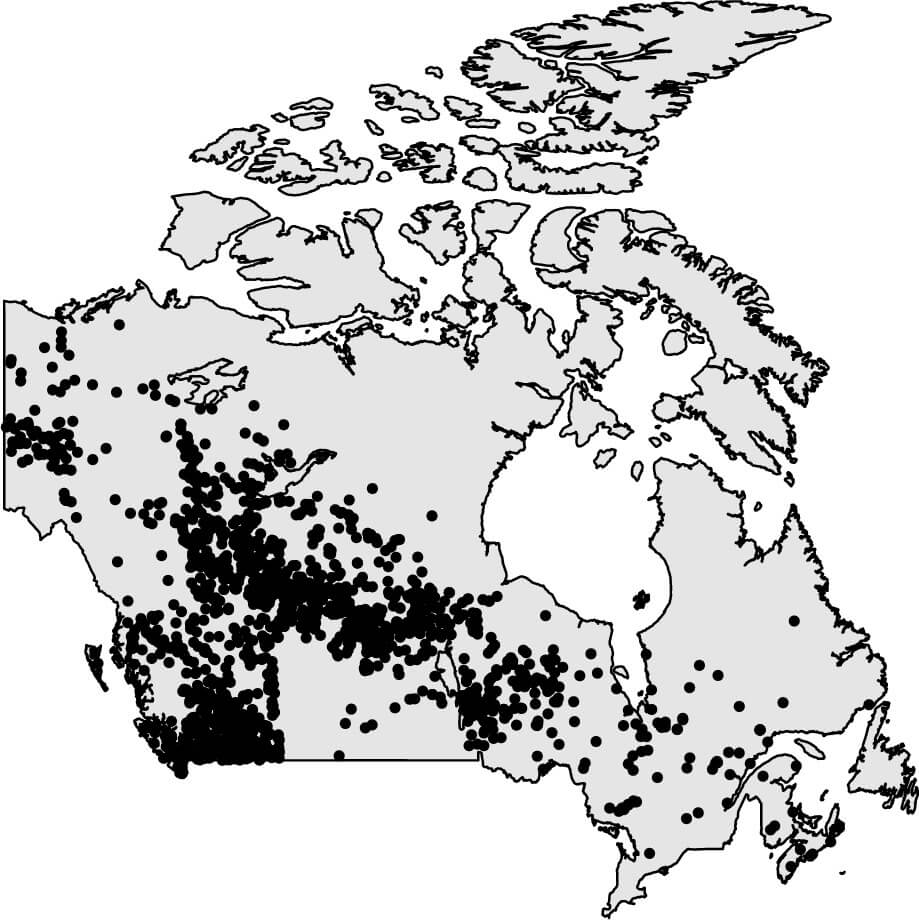
La Estadística Espacial se encuentra detrás de muchas de nuestras decisiones cotidianas. Se utiliza en los sistemas de predicción de emergencias, permitiendo anticipar fenómenos como inundaciones o incendios forestales. En regiones especialmente afectadas por los fuegos, como Galicia, se han aplicado metodologías de procesos puntuales para identificar las zonas de mayor riesgo y entender las causas subyacentes. Metodologías similares se han aplicado en Canadá, donde el reto es otro: la escala inmensa del territorio y la influencia de factores climáticos extremos.
También se aplica al estudio de accidentes de tráfico provocados por fauna salvaje, un problema creciente en diversas zonas, como por ejemplo en Cataluña, donde la presencia de jabalíes o ciervos en los aledaños de la red de carreteras genera importantes riesgos para la seguridad vial. En contextos urbanos, como Río de Janeiro, el análisis espacial de los accidentes de tráfico ha permitido detectar patrones relacionados con las horas punta y la calidad del diseño urbano.
¿Qué ocurre cuando el mapa se mueve?
Hasta ahora hemos visto cómo la Estadística Espacial nos ayuda a analizar dónde suceden las cosas. Pero, ¿qué pasa cuando esas cosas cambian con el tiempo? No es lo mismo saber que hay incendios forestales en cierto ayuntamiento, que saber además que ocurren mayormente en octubre. Es aquí donde entre en juego la Estadística Espacio-Temporal, que analiza simultáneamente el lugar y el momento.
Este tipo de análisis permite detectar patrones dinámicos, desde cómo se propaga una enfermedad a cómo evoluciona un incendio. También es clave para entender el cambio climático, el consumo energético o el comportamiento en redes sociales. Lo que antes era una foto fija, ahora se convierte en una película en constante movimiento que revela mucho más.
Conclusión
Como hemos podido observar a lo largo de estas líneas, la Estadística Espacial aporta una dimensión fundamental al análisis de datos: el lugar. En muchos contextos no basta con saber cuánto ocurre algo, sino que es igual de importante saber dónde y cómo se distribuye sobre el territorio.
El auge de tecnologías como los sensores móviles, los satélites o el GPS de nuestros teléfonos ha disparado la cantidad de datos con ubicación y marca de tiempo. Incorporar la información geográfica en los análisis permite detectar patrones, priorizar intervenciones y tomar decisiones informadas. En un entorno cada vez más conectado, donde los datos se generan en tiempo real y a distintas escalas, entender la dimensión espacial ya no es opcional, se ha convertido en una necesidad.
Referencias
- Borrajo, M. I., Comas, C., Costafreda-Aumedes, S. y Mateu, J. (2021). Stochastic smoothing of point processes for wildlife-vehicle collisions on road networks. Stochastic Environmental Research and Risk Assessment, 1-15. doi: 10.1007/s00477-021-02072-3
- Borrajo, M. I., González-Manteiga, W. y Martínez-Miranda, M. D. (2020). Bootstrapping kernel intensity estimation for inhomogeneous point processes with spatial covariates. Computational Statistics & Data Analysis, 144, 106875. doi: 10.1016/j.csda.2019.106875
- Borrajo, M. I., González-Manteiga, W. y Martínez-Miranda, M. D. (2020). Testing for significant differences between two spatial patterns using covariates. Spatial Statistics, 40, 100. doi: 10.1016/j.spasta.2019.100379
- Cressie, N. (2015). Statistics for spatial data. John Wiley & Sons. doi: 10.1002/9781119115151
- González-Pérez, I., Borrajo, M. I. y González-Manteiga, W. (2025). Nonparametric testing of first-order structure in point processes on linear networks. Statistical Papers, 66(2), 42. doi: 10.1007/s00362-024-01657-8

María Isabel Borrajo García
Doctorado en Matemáticas.

Cortesía de Muy Interesante
Dejanos un comentario: