Durante siglos, la pregunta de quién escribió la Biblia ha estimulado debates académicos, religiosos y culturales. Muchos estudiosos han defendido que los libros bíblicos fueron compuestos por distintos autores o grupos en diferentes momentos históricos, pero sin pruebas concluyentes. No hace demasiado tiempo que salió un estudio que defendía la autora de más de 40 autores de la Biblia al completo. Ahora, una investigación reciente, liderada por matemáticos y expertos en lenguas antiguas, ha aplicado una técnica basada en inteligencia artificial (IA) para identificar estilos de escritura en los primeros textos del Antiguo Testamento. Los resultados no solo respaldan teorías previas, sino que añaden una herramienta objetiva, cuantificable y transparente para abordar uno de los mayores enigmas de la historia textual.
Uno de los aspectos más atractivos de este estudio es cómo comenzó. Shira Faigenbaum-Golovin, matemática de la Universidad de Duke, empezó analizando fragmentos de cerámica antigua para determinar si fueron escritos por distintas manos. Lo que parecía una colaboración puntual con arqueólogos evolucionó en una investigación más ambiciosa: aplicar modelos estadísticos de vanguardia al análisis lingüístico de la Biblia hebrea, concretamente al llamado Enneateuco, los primeros nueve libros del Antiguo Testamento.
Identificar estilos con matemáticas
La premisa del estudio es sencilla, pero poderosa: si diferentes autores o grupos de escribas redactaron partes de la Biblia, es posible que su forma de escribir deje rastros detectables en la frecuencia de palabras. Para poner a prueba esta idea, el equipo definió tres grandes conjuntos de textos (o “corpora”) ampliamente reconocidos en los estudios bíblicos: los pasajes más antiguos del Deuteronomio (D), los textos de la llamada Historia Deuteronomista (DtrH), y los escritos sacerdotales (P), con textos tomados de Levítico, Números y Éxodo.
Lo innovador fue el enfoque técnico. En lugar de usar aprendizaje automático clásico, que requiere grandes cantidades de datos, el equipo aplicó un método estadístico sensible a variaciones sutiles en la frecuencia de palabras: la llamada HC-discrepancy. Esta herramienta, basada en la teoría de la “Higher Criticism” estadística, permite comparar un capítulo con un corpus de referencia y cuantificar si es probable que compartan autoría o no.
El modelo analiza combinaciones de palabras (n-gramas) extraídas en su forma de lema —una especie de raíz base— para evitar distorsiones gramaticales. A partir de ahí, calcula qué tan parecida es la distribución de esas palabras a la de los textos de referencia, y genera un valor que indica si hay compatibilidad o discrepancia de autoría. “La puntuación obtenida (HC) refleja el nivel de diferencia entre dos textos comparados a partir del uso de palabras”, explican los autores en el estudio.

Resultados que confirman y matizan
Los resultados fueron claros. Los textos de D y DtrH comparten una fuerte cercanía estilística, mientras que los textos sacerdotales (P) se separan notablemente. Esta diferencia no sorprende a los expertos en estudios bíblicos, pero lo novedoso es que se ha confirmado ahora mediante una herramienta estadística reproducible y transparente.
Además, el modelo fue capaz de clasificar correctamente el 84 % de los capítulos del conjunto inicial en su corpus de origen, una cifra considerable dado que muchos textos bíblicos han sido editados y reeditados a lo largo de los siglos. Las tasas de acierto para P fueron especialmente altas (95 %), mientras que D y DtrH obtuvieron 78 % y 72 %, respectivamente. “Esto demuestra que cada corpus tiene una huella lingüística única”, concluyen los autores.
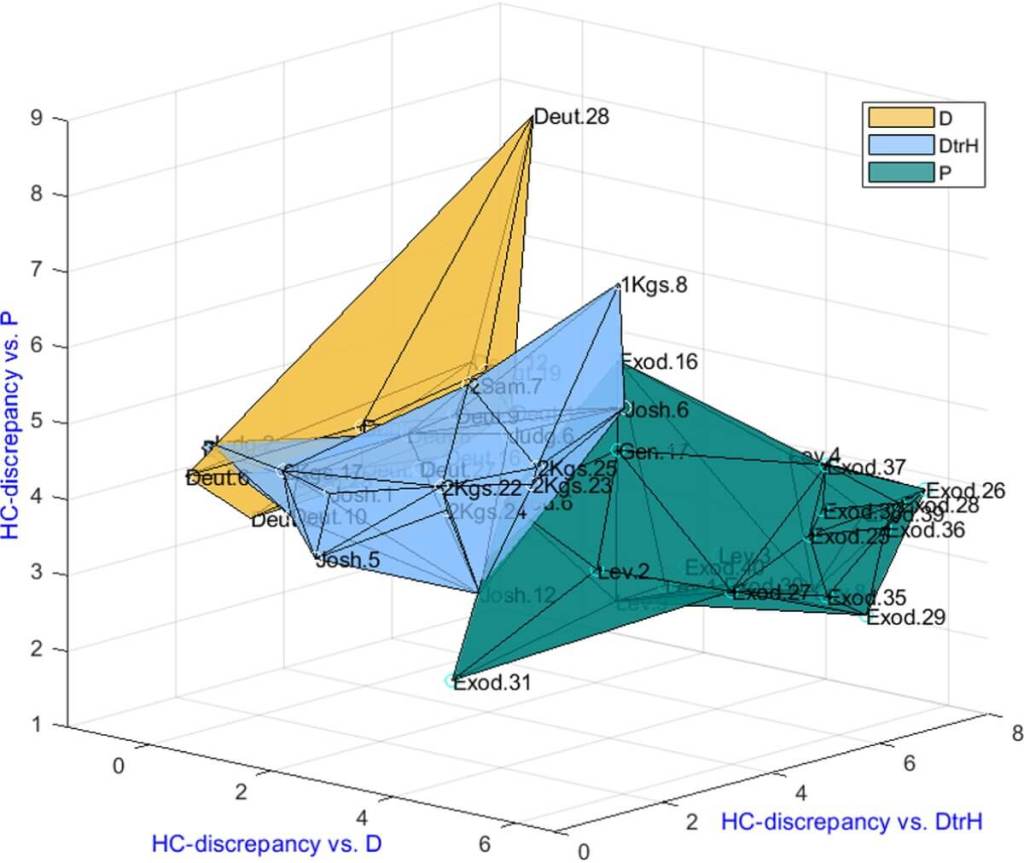
En un gráfico incluido en el artículo, se observa cómo los capítulos se agrupan en tres regiones distintas dentro de un espacio tridimensional según sus discrepancias HC respecto a cada corpus. Esta representación visual refuerza la solidez del método.
Más allá de lo evidente: casos complejos
Una parte clave del trabajo fue aplicar el modelo a capítulos cuya autoría sigue siendo motivo de debate. Por ejemplo, el análisis de las dos secciones del relato del Arca (1 Samuel y 2 Samuel) arrojó un resultado inesperado: aunque ambas tratan el mismo episodio, solo el texto de 2 Samuel mostró cercanía con DtrH. El de 1 Samuel, por el contrario, no pudo asociarse con ninguno de los tres estilos identificados, lo que sugiere un origen diferente y más antiguo, posiblemente del reino del norte de Israel.
También se analizaron otros fragmentos del Génesis, Jueces, Proverbios, Crónicas y Ester. En estos casos, los resultados fueron mixtos. Algunos textos fueron claramente diferentes de los tres corpora, como el Libro de Ester, mientras que otros, como el llamado “Jacob temprano” en Génesis, mostraron cierta cercanía con el corpus D. El modelo, por tanto, no se limita a confirmar lo que ya se sabía, sino que proporciona nuevas pistas para investigar episodios difíciles de clasificar.
Incluso cuando el modelo y los expertos no coincidieron en la clasificación de algunos capítulos, los investigadores pudieron identificar las palabras que generaban la discrepancia. Por ejemplo, la presencia frecuente de términos como “oro”, “arca” o “cubito” (en hebreo: זהב, ארון, אמה) en Éxodo 25 fue decisiva para atribuirlo al corpus P y no a D. Este nivel de detalle permite a los estudiosos comprobar por qué el algoritmo tomó ciertas decisiones, lo que refuerza su utilidad y transparencia.

Limitaciones y validación del método
A pesar de sus fortalezas, el método también presenta limitaciones. Una de ellas es la longitud de los textos. Cuantos más versículos tiene un capítulo, más confiable es la atribución. En los capítulos más cortos (menos de 20 versículos), la tasa de error aumenta. Esto es relevante, ya que muchos fragmentos antiguos son precisamente muy breves.
Otra limitación es el desequilibrio entre los corpora. El corpus P tiene más capítulos y más vocabulario disponible, lo que facilita su identificación. En cambio, D y DtrH, al ser más similares entre sí y tener menos datos, presentan más problemas de clasificación. Aun así, el sistema fue capaz de mantener una precisión alta incluso en condiciones desfavorables, con un 80 % de acierto en textos tan cortos como 10 versículos.
Para validar la robustez del modelo, los autores realizaron múltiples pruebas cruzadas. Una de ellas consistió en generar textos aleatorios con la misma frecuencia de palabras y verificar si el modelo podía distinguirlos correctamente. El margen de error obtenido fue bajo (4 %), lo que refuerza la fiabilidad del enfoque.
Una herramienta para la historia
El estudio no solo refuerza hipótesis anteriores sobre la composición múltiple de la Biblia, sino que abre nuevas posibilidades para el análisis de textos antiguos. El equipo ya está aplicando esta técnica a otros documentos como los Rollos del Mar Muerto o relatos patriarcales del Génesis.
Este tipo de herramientas permite abordar preguntas antiguas con técnicas modernas. Y, lo más importante, lo hacen de forma que los expertos puedan entender, revisar y debatir los resultados sin depender de cajas negras o algoritmos opacos.
Como concluyen los autores en el artículo: “Nuestro marco computacional puede ayudar a resolver el reto de la autoría al estimar la probabilidad de atribuir un nuevo texto a un corpus determinado, ofreciendo además las razones lingüísticas de dicha atribución”.
Más que reemplazar a los expertos, este enfoque busca complementar su trabajo con herramientas objetivas. Y en un campo tan complejo como los estudios bíblicos, toda ayuda cuantificable, reproducible y abierta es bienvenida.
Referencias
- Shira Faigenbaum-Golovin, Alon Kipnis, Axel Bühler, Eli Piasetzky, Thomas Römer, Israel Finkelstein. Critical biblical studies via word frequency analysis: Unveiling text authorship. PLOS One 20(6): e0322905. https://doi.org/10.1371/journal.pone.0322905.
Cortesía de Muy Interesante
Dejanos un comentario: